|

|
|
joe.degol@outlook.com |
Curriculum Vitae |
|
Scholar |
2014 NDSEG Essay |
2014 NSF GRFP Essay |
PUBLICATIONS |
||||
|---|---|---|---|---|

|
Optimizing Fiducial Marker Placement For Improved Visual Localization
Qiangqiang Huang,
Joseph DeGol,
Victor Fragoso,
Sudipta Sinha,
John Leonard
2023 Robotics And Automation Letters (RAL '23) Adding fiducial markers to a scene is a well-known strategy for making visual localization algorithms more robust. Traditionally, these marker locations are selected by humans who are familiar with visual localization techniques. This letter explores the problem of automatic marker placement within a scene. Specifically, given a predetermined set of markers and a scene model, we compute optimized marker positions within the scene that can improve accuracy in visual localization. Our main contribution is a novel framework for modeling camera localizability that incorporates both natural scene features and artificial fiducial markers added to the scene. We present optimized marker placement (OMP), a greedy algorithm that is based on the camera localizability framework. We have also designed a simulation framework for testing marker placement algorithms on 3D models and images generated from synthetic scenes. We have evaluated OMP within this testbed and demonstrate an improvement in the localization rate by up to 20 percent on four different scenes. |
|||
|
Learning to Detect Scene Landmarks for Camera Localization
Tien Do,
Ondrej Miksik,
Joseph DeGol,
Hyun Soo Park,
Sudipta Sinha
2022 Conference on Computer Vision and Pattern Recognition (CVPR '22) Modern camera localization methods that use image retrieval, feature matching, and 3D structure-based pose estimation require long-term storage of numerous scene images or a vast amount of image features. This can make them unsuitable for resource constrained VR/AR devices and also raises privacy concerns. We present a new learned camera localization technique that eliminates the need to store features or a detailed 3D point cloud. Our key idea is to implicitly encode the appearance of a sparse yet salient set of 3D scene points into a convolutional neural network (CNN) that can detect these scene points in query images whenever they are visible. We refer to these points as scene landmarks. We show that a CNN can be trained to regress bearing vectors for such landmarks even when they are not within the camera’s field-of-view. We demonstrate that the predicted landmarks yield accurate pose estimates and our method outperforms DSAC*, the state-of-the art in learned localization. Furthermore, extending HLoc by combining its correspondences with our predictions boosts its accuracy even further. |
|||

|
PatchMatch-RL: Deep MVS with Pixelwise Depth, Normal, and Visibility
Jae Yong Lee,
Joseph DeGol,
Chuhang Zou,
Derek Hoiem
2021 International Conference on Computer Vision (ICCV '21) Recent learning-based multi-view stereo (MVS) methods show excellent performance with dense cameras and small depth ranges. However, non-learning based approaches still outperform for scenes with large depth ranges and sparser wide-baseline views, in part due to their PatchMatch optimization over pixelwise estimates of depth, normals, and visibility. In this paper, we propose an end-to-end trainable PatchMatch-based MVS approach that combines advantages of trainable costs and regularizations with pixelwise estimates. To overcome the challenge of the non-differentiable PatchMatch optimization that involves iterative sampling and hard decisions, we use reinforcement learning to minimize expected photometric cost and maximize likelihood of ground truth depth and normals. We incorporate normal estimation by using dilated patch kernels and propose a recurrent cost regularization that applies beyond frontal plane-sweep algorithms to our pixelwise depth/normal estimates. We evaluate our method on widely used MVS benchmarks, ETH3D and Tanks and Temples (TnT). On ETH3D, our method outperforms other recent learning-based approaches and performs comparably on advanced TnT. |
Oral Paper (13%) |
||

|
PatchMatch-Based Neighborhood Consensus for Semantic Correspondence
Jae Yong Lee,
Joseph DeGol,
Victor Fragoso,
Sudipta Sinha
2021 Conference on Computer Vision and Pattern Recognition (CVPR '21) We address estimating dense correspondences between two images depicting different but semantically related scenes. End-to-end trainable deep neural networks incorporating neighborhood consensus cues are currently the best methods for this task. However, these architectures require exhaustive matching and 4D convolutions over matching costs for all pairs of feature map pixels. This makes them computationally expensive. We present a more efficient neighborhood consensus approach based on PatchMatch. For higher accuracy, we propose to use a learned local 4D scoring function for evaluating candidates during the PatchMatch iterations. We have devised an approach to jointly train the scoring function and the feature extraction modules by embedding them into a proxy model which is end-to-end differentiable. The modules are trained in a supervised setting using a cross-entropy loss to directly incorporate sparse keypoint supervision. Our evaluation on PF-Pascal and SPair-71K shows that our method significantly outperforms the state-of-the-art on both datasets while also being faster and using less memory. |
|||

|
Improving Structure from Motion with Reliable ResectioningA common cause of failure in structure-from-motion (SfM) is misregistration of images due to visual patterns that occur in more than one scene location. Most work to solve this problem ignores image matches that are inconsistent according to the statistics of the tracks graph, but these methods often need to be tuned for each dataset and can lead to reduced completeness of normally good reconstructions when valid matches are removed. Our key idea is to address ambiguity directly in the reconstruction process by using only a subset of reliable matches to determine resectioning order and the initial pose. We also introduce a new measure of similarity that adjusts the influence of feature matches based on their track length. We show this improves reconstruction robustness for two state-of-the-art SfM algorithms on many diverse datasets. |
Oral Paper (13.2%) |
||
|
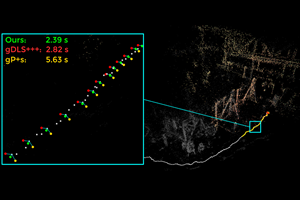
gDLS*: Generalized Pose-and-Scale Estimation Given Scale and Gravity Priors
Victor Fragoso,
Joseph DeGol,
Gang Hua
2020 Conference on Computer Vision and Pattern Recognition (CVPR '20) Many real-world applications in augmented reality (AR), 3D mapping, and robotics require both fast and accurate estimation of camera poses and scales from multiple images captured by multiple cameras or a single moving camera. Achieving high speed and maintaining high accuracy in a pose-and-scale estimator are often conflicting goals. To simultaneously achieve both, we exploit a priori knowledge about the solution space. We present gDLS*, a generalized-camera-model pose-and-scale estimator that utilizes rotation and scale priors. gDLS* allows an application to flexibly weigh the contribution of each prior, which is important since priors often come from noisy sensors. Compared to state-of-the-art generalized-pose-and-scale estimators (e.g. gDLS), our experiments on both synthetic and real data consistently demonstrate that gDLS* accelerates the estimation process and improves scale and pose accuracy. |
|||

|
Towards Vision Based Robots for Monitoring Built EnvironmentsIn construction, projects are typically behind schedule and over budget, largely due to the difficulty of progress monitoring. Once a structure (e.g. a bridge) is built, inspection becomes an important yet dangerous and costly job. We can provide a solution to both problems if we can simplify or automate visual data collection, monitoring, and analysis. In this work, we focus specifically on improving autonomous image collection, building 3D models from the images, and recognizing materials for progress monitoring using the images and 3D models. |
|||

|
Improved Structure from Motion Using Fiducial Marker Matching
Joseph DeGol,
Timothy Bretl,
Derek Hoiem
2018 Springer European Conference on Computer Vision (ECCV '18) In this paper, we present an incremental structure from motion (SfM) algorithm that significantly outperforms existing algorithms when fiducial markers are present in the scene, and that matches the performance of existing algorithms when no markers are present. Our algorithm uses markers to limit potential incorrect image matches, change the order in which images are added to the reconstruction, and enforce new bundle adjustment constraints. To validate our algorithm, we introduce a new dataset with 16 image collections of large indoor scenes with challenging characteristics (e.g., blank hallways, glass facades, brick walls) and with markers placed throughout. We show that our algorithm produces complete, accurate reconstructions on all 16 image collections, most of which cause other algorithms to fail. Further, by selectively masking fiducial markers, we show that the presence of even a small number of markers can improve the results of our algorithm. |
|||

|
FEATS: Synthetic Feature Tracks for Structure from Motion Evaluation
Joseph DeGol,
Jae Yong Lee,
Rajbir Kataria,
Daniel Yuan,
Timothy Bretl,
Derek Hoiem
2018 International Conference on 3D Vision (3DV '18) We present FEATS (Feature Extraction and Tracking Simulator), that synthesizes feature tracks using a camera trajectory and scene geometry (e.g. CAD, laser, multi-view stereo). We introduce 2D feature and matching noise models that can be controlled through a simple set of parameters. We also provide a new dataset of images and ground truth camera pose. We process this data (and a synthetic version) with several current SfM algorithms and show that the synthetic tracks are representative of the real tracks. We then demonstrate several practical uses of FEATS: (1) we generate hundreds of trajectories with varying noise and show that COLMAP is more robust to noise than OpenSfM and VisualSfM; and (2) we calculate 3D point error and show that accurate camera pose estimates do not guarantee accurate 3D maps. |
|||

|
Geometry and Appearance Based Reasoning of Construction Progress Monitoring
Kevin Han,
Joseph DeGol,
Mani Golparvar-Fard
ASCE Journal of Construction Engineering and Management, February 2018 Although adherence to project schedules and budgets is most highly valued by project owners, more than 53% of typical construction projects are behind schedule and more than 66% suffer from cost overruns, partly due to inability to accurately capture construction progress. To address these challenges, this paper presents new geometry and appearance based reasoning methods for detecting construction progress, which has the potential to provide more frequent progress measures using visual data that are already being collected by general contractors. The initial step of geometry-based filtering detects the state of construction of Building Information Modeling (BIM) elements (e.g. in-progress, completed). The next step of appearance-based reasoning captures operation-level activities by recognizing different material types. Two methods have been investigated for the latter step: a texture-based reasoning for image-based 3D point clouds and color-based reasoning for laser scanned point clouds. This paper presents two case studies for each reasoning approach for validating the proposed methods. The results demonstrate the effectiveness and practical significances of the proposed methods. |
|||

|
ChromaTag: A Colored Marker and Fast Detection Algorithm
Joseph DeGol,
Timothy Bretl,
Derek Hoiem
2017 International Conference on Computer Vision (ICCV '17) Current fiducial marker detection algorithms rely on marker IDs for false positive rejection. Time is wasted on potential detections that will eventually be rejected as false positives. We introduce ChromaTag, a fiducial marker and detection algorithm designed to use opponent colors to limit and quickly reject initial false detections and gray scale for precise localization. Through experiments, we show that ChromaTag is significantly faster than current fiducial markers while achieving similar or better detection accuracy. We also show how tag size and viewing direction effect detection accuracy. Our contribution is significant because fiducial markers are often used in real-time applications (e.g. marker assisted robot navigation) where heavy computation is required by other parts of the system. |
|||

|
Automatic Grasp Selection using a Camera in a Hand Prosthesis
Joseph DeGol,
Aadeel Akhtar,
Bhargava Manja,
Tim Bretl
2016 International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC '16) In this paper, we demonstrate how automatic grasp selection can be achieved by placing a camera in the palm of a prosthetic hand and training a convolutional neural network on images of objects with corresponding grasp labels. Our labeled dataset is built from common graspable objects curated from the ImageNet dataset and from images captured from our own camera that is placed in the hand. We achieve a grasp classification accuracy of 93.2% and show through realtime grasp selection that using a camera to augment current electromyography controlled prosthetic hands may be useful. |
Oral Paper Best Student Paper (3rd) |
||

|
Geometry-Informed Material Recognition
Joseph DeGol,
Mani Golparvar-Fard,
Derek Hoiem
2016 Conference on Computer Vision and Pattern Recognition (CVPR '16) Our goal is to recognize material categories using images and geometry information. In many applications, such as construction management, coarse geometry information is available. We investigate how 3D geometry (surface normals, camera intrinsic and extrinsic parameters) can be used with 2D features (texture and color) to improve material classification. We introduce a new dataset, GeoMat, which is the first to provide both image and geometry data in the form of: (i) training and testing patches that were extracted at different scales and perspectives from real world examples of each material category, and (ii) a large scale construction site scene that includes 160 images and over 800,000 hand labeled 3D points. Our results show that using 2D and 3D features both jointly and independently to model materials improves classification accuracy across multiple scales and viewing directions for both material patches and images of a large scale construction site scene. |
Spotlight Paper (9.7%) |
||

|
A Passive Mechanism for Relocating Payloads with a Quadrotor
Joseph DeGol,
David Hanley,
Navid Aghasadeghi,
Tim Bretl
2015 International Conference on Intelligent Robots and Systems (IROS '15) We present a passive mechanism for quadrotor vehicles and other hover-capable aerial robots based on the use of a cam-follower mechanism. This mechanism has two mating parts, one attached to the quadrotor and the other attached to a payload. These two parts are joined by a toggle switch— push to connect, push to disconnect—that is easy to activate with the quadrotor by varying thrust. We discuss the design parameters and provide an inertial model for our mechanism. With hardware experiments, we demonstrate the use of this passive mechanism to autonomously place a wireless camera in several different locations on the underside of a steel beam. Our mechanism is open source and can be easily fabricated with a 3D printer. |
|||

|
A Clustering Approach for Detecting Moving Objects Captured by a Moving Aerial Vehicle
Joseph DeGol,
Myra Nam
2014 International Conference on Acoustics, Speech, and Signal Processing (ICASSP '14) We propose a novel approach to motion detection in scenes captured from a camera onboard an aerial vehicle. In particular, we are interested in detecting small objects such as cars or people that move slowly and independently in the scene. Slow motion detection in an aerial video is challenging because it is difficult to differentiate object motion from camera motion. We adopt an unsupervised learning approach that requires a grouping step to define slow object motion. The grouping is done by building a graph of edges connecting dense feature keypoints. Then, we use camera motion constraints over a window of adjacent frames to compute a weight for each edge and automatically prune away dissimilar edges. This leaves us with groupings of similarly moving feature points in the space, which we cluster and differentiate as moving objects and background. With a focus on surveillance from a moving aerial platform, we test our algorithm on the challenging VIRAT aerial data set [1] and provide qualitative and quantitative results that demonstrate the effectiveness of our detection approach. |
|||
|
Don't drop it! Pick it up and storyboard
Shahtab Wahid,
D. Scott McCrickard,
Joseph DeGol,
Nina Elias,
Steve Harrison
2011 Conference on Human Factors in Computing Systems (CHI '11) Storyboards offer designers a way to illustrate a narrative. Their creation can be enabled by tools supporting sketching or widget collections. As designers often incorporate previous ideas, we contribute the notion of blending the reappropriation of artifacts and their design tradeoffs with storyboarding. We present PIC-UP, a storyboarding tool supporting reappropriation, and report on two studies--a long-term investigation with novices and interviews with experts. We discuss how it may support design thinking, tailor to different expertise levels, facilitate reappropriation during storyboarding, and assist with communication. |
MOUNTAINEERING |
||||||
|---|---|---|---|---|---|---|


|
Wheeler Peakfrom Williams Lake Trailhead via West Face |
September 4, 2023 |
13,161 ft4,011 m |

|
||


|
Kit Carson Peakfrom Willow and South Crestone Trailhead via West Ridge |
September 2, 2023 |
14,165 ft4,317 m |

|
||


|
Challenger Pointfrom Willow and South Crestone Trailhead via North Slopes |
September 2, 2023 |
14,081 ft4,292 m |
|
||


|
Mount Eolusfrom Needleton Trailhead via Northeast Ridge |
August 30, 2023 |
14,084 ft4,293 m |
|
||


|
North Eolusfrom Needleton Trailhead via South Ridge |
August 30, 2023 |
14,039 ft4,279 m |
|
||


|
Windom Peakfrom Needleton Trailhead via West Ridge |
August 30, 2023 |
14,087 ft4,294 m |
|
||


|
Sunlight Peakfrom Needleton Trailhead via South Slopes |
August 30, 2023 |
14,059 ft4,285 m |
|
||


|
Crestone Peakfrom South Colony Lakes Trailhead via South Face |
September 23, 2022 |
14,294 ft4,356 m |
|
||


|
Blanca Peakfrom Lake Como Trailhead via Northwest Face |
September 18, 2022 |
14,345 ft4,372 m |
|
||


|
San Luis Peakfrom Stewart Creek Trailhead via Northeast Ridge |
September 5, 2022 |
14,014 ft4,271 m |
|
||


|
Wetterhorn Peakfrom Matterhorn Creek Trailhead via Southeast Ridge |
Septemebr 3, 2022 |
14,015 ft4,271 m |
|
||


|
Uncompahgre Peakfrom Nellie Creek Trailhead via South Ridge |
August 27, 2022 |
14,309 ft4,361 m |
|
||


|
Mount Sneffelsfrom Blue Lakes Trailhead via South Slopes |
August 24, 2022 |
14,150 ft4,312 m |
|
||


|
Handies Peakfrom American Basin Trailhead via West Slopes |
August 14, 2022 |
14,048 ft4,282 m |
|
||


|
Mount Anterofrom Baldwin Gulch Trailhead via West Slopes |
August 12, 2022 |
14,276 ft4,351 m |
|
||


|
Mount Shuksan
from Shannon Ridge Trailhead via |
August 6, 2022 |
9,131 ft2,783 m |

|
||


|
Redcloud Peakfrom Silver Creek/Grizzly Gulch Trailhead via Sunshine Peak |
October 3, 2021 |
14,034 ft4,278 m |
|
||


|
Sunshine Peakfrom Silver Creek/Grizzly Gulch Trailhead via Northwest Face |
October 3, 2021 |
14,001 ft4,268 m |
|
||


|
Humboldt Peakfrom South Colony Lakes Trailhead via West Ridge |
September 25, 2021 |
14,064 ft4,287 m |
|
||


|
Mount of the Holy Crossfrom Half Moon Trailhead via North Ridge |
September 19, 2021 |
14,005 ft4,269 m |
|
||


|
Mauna Keafrom North Cottonwood Trailhead via West Slopes |
July 5, 2021 |
13,803 ft4,207 m |

|
||


|
Mount Columbiafrom North Cottonwood Trailhead via West Slopes |
October 3, 2020 |
14,073 ft4,289 m |
|
||


|
Mount Harvardfrom North Cottonwood Trailhead via South Slopes |
October 2, 2020 |
14,420 ft4,395 m |
|
||


|
Torreys Peakfrom Grays Peak Trailhead via South Slopes |
October 1, 2020 |
14,267 ft4,349 m |
|
||


|
Grays Peakfrom Grays Peak Trailhead via North Slopes |
October 1, 2020 |
14,270 ft4,350 m |
|
||


|
Mount Saint Helensfrom Climbers Bivouac Trailhead via Monitor Ridge |
September 29, 2020 |
8,365 ft2,550 m |
|
||


|
Mount Bakerfrom Scott Paul Trail via Squak Glacier |
August 5, 2020 |
10,781 ft3,286 m |
|
||


|
Mount Adamsfrom South Climb Trail via South Spur |
July 25, 2020June 20, 2021 |
12,276 ft3,742 m |
|
||


|
Huron Peakfrom South Winfield Trailhead via Northwest Slopes |
July 26, 2019 |
14,003 ft4,268 m |
|
||


|
Tabaguache Peakfrom Blank Gulch Trailhead via Mount Shavano (Combo Route) |
July 25, 2019 |
14,155 ft4,314 m |
|
||


|
Mount Shavanofrom Blank Gulch Trailhead via East Slopes |
July 25, 2019 |
14,229 ft4,337 m |
|
||


|
Missouri Mountainfrom Missouri Gulch Trailhead via Northwest Ridge |
July 22, 2019 |
14,067 ft4,288 m |
|
||


|
Mount Princetonfrom Mount Princeton Trailhead via East Slopes |
July 20, 2019 |
14,197 ft4,327 m |
|
||


|
Mount Shermanfrom Iowa Gulch Trailhead via West Slopes |
July 19, 2019 |
14,036 ft4,278 m |
|
||


|
Mount Yalefrom Denny Creek Trailhead via Southwest Slopes |
July 15, 2019 |
14,196 ft4,327 m |
|
||


|
La Plata Peakfrom La Plata Trailhead via Northwest Ridge |
July 15, 2018 |
14,336 ft4,370 m |
|
||


|
Mount Massivefrom Mount Massive Trailhead via East Slopes |
July 13, 2018 |
14,421 ft4,396 m |
|
||


|
Mount Elbertfrom South Mount Elbert Trailhead via East Ridge |
July 6, 2018August 23, 2017 |
14,433 ft4,399 m |
|
||


|
Castle Peakfrom Castle Creek Trailhead via Northeast Ridge |
July 4, 2018 |
14,265 ft4,348 m |
|
||


|
Mount Oxfordfrom Missouri Gulch Trailhead via Mount Belford |
June 24, 2018 |
14,153 ft4,314 m |
|
||


|
Mount Belfordfrom Missouri Gulch Trailhead via Northwest Ridge |
June 24, 2018August 22, 2017 |
14,197 ft4,327 m |
|
||


|
Quandary Peakfrom Quandary Trailhead via East Ridge |
June 18, 2018 |
14,265 ft4,348 m |
|
||


|
Mount Brossfrom Kite Lake Trailhead via Mount Lincoln (Combo Route) |
June 16, 2018September 14, 2021 |
14,172 ft4,320 m |
|
||


|
Mount Lincolnfrom Kite Lake Trailhead via Mount Cameron (Combo Route) |
June 16, 2018September 14, 2021 |
14,286 ft4,354 m |
|
||


|
Mount Cameronfrom Kite Lake Trailhead via Mount Democrat (Combo Route) |
June 16, 2018September 14, 2021 |
14,238 ft4,340 m |
|
||


|
Mount Democratfrom Kite Lake Trailhead via East Slopes (Combo Route) |
June 16, 2018September 14, 2021 |
14,148 ft4,312 m |
|
||


|
Mount Bierstadtfrom Guanella Pass Trailhead via West Slopes |
June 14, 2018 |
14,060 ft4,285 m |
|
||


|
Mount Evansfrom Echo Lake Trailhead via West Ridge |
June 9, 2018 |
14,264 ft4,348 m |
|
||


|
Pikes Peakfrom Barr Trailhead via East Slopes |
August 21, 2017 |
14,110 ft4,301 m |
|
||


|
White Mountain Peakfrom Barcroft Gate Trailhead via South Face |
June 25, 2016 |
14,252 ft4,344 m |

|
◼ |
Lead Rock Climbing Mentorship |
KAF Adventures, Seattle, WA. |
June 2023 - Sept 2023 |
|||
◼ |
Mountaineering: Leadership |
KAF Adventures, Seattle, WA. |
Aug 19, 2021 - Aug 22, 2021 |
|||
◼ |
Mountaineering: Intermediate |
KAF Adventures, Seattle, WA. |
Aug 30, 2018 - Sept 1, 2018 |
|||
◼ |
Mountaineering: Beginner |
KAF Adventures, Seattle, WA. |
Sept 1, 2018 |